Cortex by Aryan Arora
Documentation
49 MCP tools. Knowledge graph. Autonomous agent coordination. FastAPI + PostgreSQL + Railway.
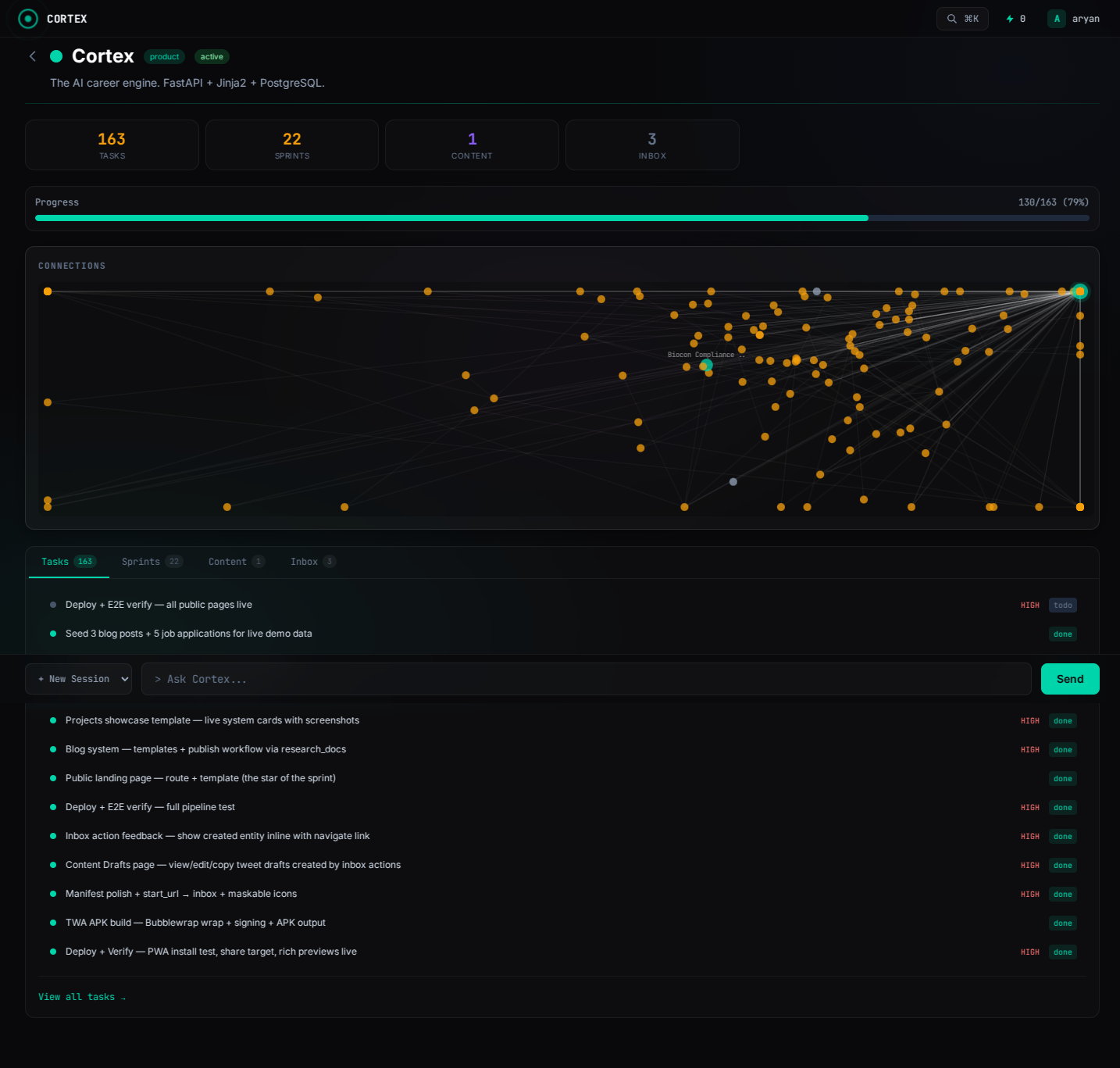
Overview
Cortex is an AI infrastructure system that manages the full software development lifecycle through autonomous agents. It coordinates parallel development teams, tracks research, manages sprints, and maintains a knowledge graph connecting every entity in the system.
It's not a framework or a library. It's a production system that runs every day, deployed on Railway, serving both human users via browser and AI agents via MCP protocol.
Tech Stack
| Layer | Technology | Why |
|---|---|---|
| Web Framework | FastAPI 0.115 | Async-first, auto-generated OpenAPI docs, dependency injection |
| Templates | Jinja2 | Server-side rendering, no build step, instant deploys |
| Database | PostgreSQL 16 | Relational + graph queries via CTEs, battle-tested at scale |
| DB Driver | asyncpg | 3x throughput over SQLAlchemy on concurrent agent workloads |
| Agent Protocol | MCP (Model Context Protocol) | Standards-based tool calling, extensible, multi-agent support |
| Deployment | Railway + Dockerfile | Git push to deploy, zero infra management |
| CI/CD | GitHub Actions | Syntax check + pytest on PostgreSQL 16 service container |
| Auth | Cookie (human) + API Key (agent) | Dual-mode: browsers get sessions, agents get header auth |
Architecture
Cortex is a modular monolith. Every component communicates through the database and internal function calls — no microservice overhead for a system that runs on a single Railway instance.
System Architecture
FastAPI + PostgreSQL + Jinja2 SSR with dual auth (cookie + API key), deployed on Railway with GitHub Actions CI/CD.
graph LR
subgraph Clients
PWA[Browser / PWA]
Agents[Claude Agents]
end
subgraph Core["Cortex Core"]
API[FastAPI<br/>uvicorn async]
Jinja[Jinja2 Templates<br/>SSR + mobile-first]
Auth[Dual Auth<br/>Cookie + API Key]
end
subgraph Data["Data Layer"]
PG[(PostgreSQL<br/>27+ tables)]
end
subgraph MCP["MCP Layer"]
MCPServer[MCP Server<br/>49 tools]
end
subgraph Infra["Infrastructure"]
Railway[Railway<br/>auto-deploy]
GHA[GitHub Actions<br/>CI / CD]
end
PWA -->|HTTP / WS| API
Agents -->|X-API-Key| API
API --> Jinja
API --> PG
API -->|async pool| PG
Auth -.->|guards| API
MCPServer <-->|MCP protocol| Agents
MCPServer -->|HTTP| API
GHA -->|push to main| Railway
Railway -->|hosts| API
MCP Tool Ecosystem
49 MCP tools across 17 categories enabling Claude agents to manage tasks, sprints, content, social media, and the knowledge graph.
flowchart LR
Agents[Claude Agents] -->|MCP protocol| Router[Tool Router]
Router --> T[Tasks<br/>8 tools]
Router --> S[Sprints<br/>5 tools]
Router --> G[Graph<br/>3 tools]
Router --> C[Content<br/>5 tools]
Router --> SM[Social<br/>5 tools]
Router --> R[Research<br/>3 tools]
Router --> SE[Sessions<br/>4 tools]
Router --> SY[System<br/>5 tools]
Router --> More[+9 categories<br/>11 tools]
T --> DB[(PostgreSQL<br/>27+ tables)]
S --> DB
G --> DB
SE --> DB
Knowledge Graph
12 entity types with auto-enrichment on create and boot-time backfill. 190+ nodes and 360+ edges mapping every project artifact.
graph TD
subgraph Entities["12 Entity Types"]
task((task))
sprint((sprint))
session((session))
app((app))
research((research))
revenue((revenue))
content((content))
user((user))
contact((contact))
presentation((pres.))
skill((skill))
tool((tool))
end
task -->|belongs_to| sprint
task -->|depends_on| task
session -->|created_in| sprint
app -->|belongs_to| user
research -->|part_of| sprint
content -->|created_in| session
skill -->|belongs_to| app
tool -->|belongs_to| app
subgraph Enrichment["Auto-Enrichment"]
Create[Entity Created] --> Edge[Graph Edge Inserted]
Boot[Server Boot] --> Backfill[Missing Edges Filled]
end
Sprint Orchestration
Full SDLC pipeline: plan tasks with dependency DAG, spawn parallel builder agents in isolated worktrees, verify, review, deploy, and QA.
flowchart LR
subgraph Plan["1. Plan"]
CP[cortex-plan<br/>Task decomposition]
CP --> DAG[Dependency graph<br/>topological sort]
end
subgraph Execute["2. Execute"]
CE[cortex-execute<br/>Spawn builders]
CE --> B1[Builder 1<br/>worktree-a]
CE --> B2[Builder 2<br/>worktree-b]
CE --> B3[Builder 3<br/>worktree-c]
end
subgraph BuildLoop["Builder Loop"]
Claim[claim_task] --> Build[Build + Test]
Build --> Commit[git commit]
Commit --> Report[report_done]
Report -->|next task| Claim
end
subgraph Verify["3. Verify"]
Lead[Lead Agent<br/>verify deliverables]
Lead --> Merge[Merge to main]
end
subgraph Review["4. Review"]
CR[cortex-review<br/>Security + arch check]
end
subgraph Deploy["5. Deploy"]
CD[cortex-deploy<br/>git push origin main]
CD --> Rail[Railway<br/>auto-deploy]
end
subgraph QA["6. QA"]
CQ[cortex-qa<br/>Playwright verify]
end
Plan --> Execute
B1 --> BuildLoop
B2 --> BuildLoop
B3 --> BuildLoop
BuildLoop --> Verify
Verify --> Review
Review --> Deploy
Deploy --> QA
Database
27+ tables organized into 9 clusters. Schema managed via raw SQL with asyncpg — no ORM, no migration framework.
Table Clusters
| Cluster | Tables | Purpose |
|---|---|---|
| Auth | users, user_sessions, user_project_access | Authentication, session management, project-level access |
| RBAC | authorization_model, authorization_tuples | Role-based access control with relation tuples |
| Projects | projects, sprints, tasks, task_dependencies | Sprint planning, task management, dependency graphs |
| Communication | sessions, messages | Agent sessions (Neural Link), message threads |
| Content | research_docs, content_calendar, notes | Research library, content scheduling, notes |
| Revenue | revenue_entries, revenue_goals | Financial tracking in paise (BIGINT) |
| Applications | contacts, applications, pipeline_entries | Job applications, outreach pipeline |
| Registry | skills, tools, apps | Skill registry, tool registry, app framework |
| Graph | relations | Knowledge graph edges (source_type, source_id, relation, target_type, target_id) |
Key Design Decisions
- asyncpg over SQLAlchemy — raw connection pool with explicit SQL. 3x throughput when multiple agents hit the DB concurrently.
- No migration framework —
CREATE TABLE IF NOT EXISTSwithALTER TABLE ADD COLUMN IF NOT EXISTS. Schema evolves in place. Simpler than Alembic for a single-developer system. - Financial data in paise/cents (BIGINT) — no floating point rounding errors. Ever.
- Agent user id=0 — synthetic user for API key auth. Code uses
if uid is Nonenotif not uidto avoid treating agent as unauthenticated.
API Reference
All endpoints require API key authentication. Base URL: https://cortex.stuckaryan.in/api
| Module | Endpoints | Description |
|---|---|---|
| tasks | GET/POST/PATCH/DELETE /api/tasks | Task CRUD with auto graph enrichment |
| projects | GET/POST /api/projects, /api/sprints | Projects + Sprints CRUD, bulk sprint planning |
| relations | POST /api/relations, GET /api/graph/* | Knowledge graph CRUD, traversal, bulk enrichment |
| research | GET/POST/PUT/DELETE /api/research | Research document library |
| content | GET/POST/PATCH/DELETE /api/content | Content calendar management |
| sessions | GET/POST /api/sessions | Agent sessions (Neural Link) |
| skills | GET /api/skills, POST /api/skills/sync | Skills registry, disk sync |
| tools | GET /api/tools, POST /api/tools/sync | Tool registry |
| revenue | GET/POST /api/revenue | Financial tracking |
| system | GET /health, /api/system/stats | Health checks, system metrics |
MCP Tools
49 tools across 17 categories. Agents discover tools via the MCP protocol and call them as functions. The server runs as a separate process communicating via stdio.
| Category | Tools | Examples |
|---|---|---|
| Task Management | 7 | create_task, list_tasks, claim_task, complete_task, update_task, delete_task, get_task |
| Sprint Ops | 5 | plan_sprint, get_sprint, update_sprint, list_sprints, create_sprint |
| Knowledge Graph | 3 | add_relation, enrich_graph, get_graph |
| Content Calendar | 5 | add_content, list_content, schedule_content, generate_content, optimize_tweet |
| Social Media | 4 | post_tweet, read_tweets, twitter_trends, social_stats |
| Research | 3 | add_research, get_research, search_research |
| Sessions | 4 | create_session, get_session, list_sessions, get_messages |
| Agent Coordination | 4 | checkin, checkout, heartbeat, claim_task |
| Projects | 3 | create_project, list_projects, init_project |
| System | 3 | health, list_tools, notify |
| Notes | 2 | add_note, list_notes |
| Revenue | 2 | add_revenue, list_revenue |
| Apps | 4 | register_app, list_apps, archive_app, analyze_link |
Knowledge Graph
A PostgreSQL-powered knowledge graph with 724 nodes and 1203 edges across 12 entity types.
Entity Types
Auto-Enrichment
When any entity is created with a project link, the system automatically creates a graph edge. No manual enrichment needed.
On every server boot, the system scans all entities and backfills any missing graph edges. This is how the graph went from 0 to 724 nodes on first deployment.
Relation Types
- belongs_to — task belongs_to project, sprint belongs_to project
- depends_on — task depends_on task (dependency chains)
- created_in — session created_in sprint
- part_of — skill part_of system, tool part_of category
Skills System
12 skills covering the full SDLC. Skills are loaded from disk on boot and synced to the database.
SDLC Pipeline
Each skill is a structured prompt that teaches an AI agent how to perform a specific SDLC phase. The orchestrator skill (cortex) decomposes high-level goals and routes work to the appropriate skill.
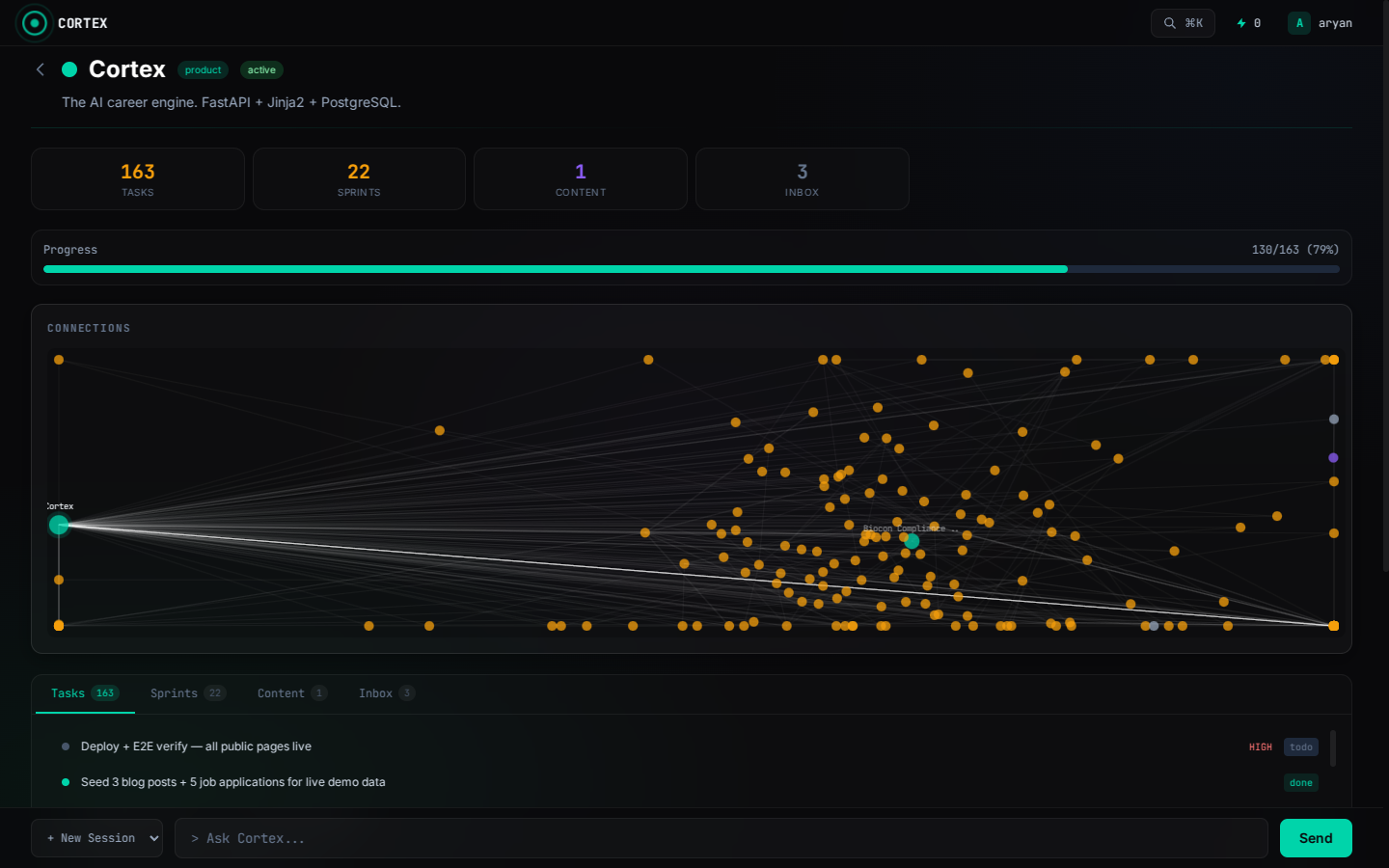
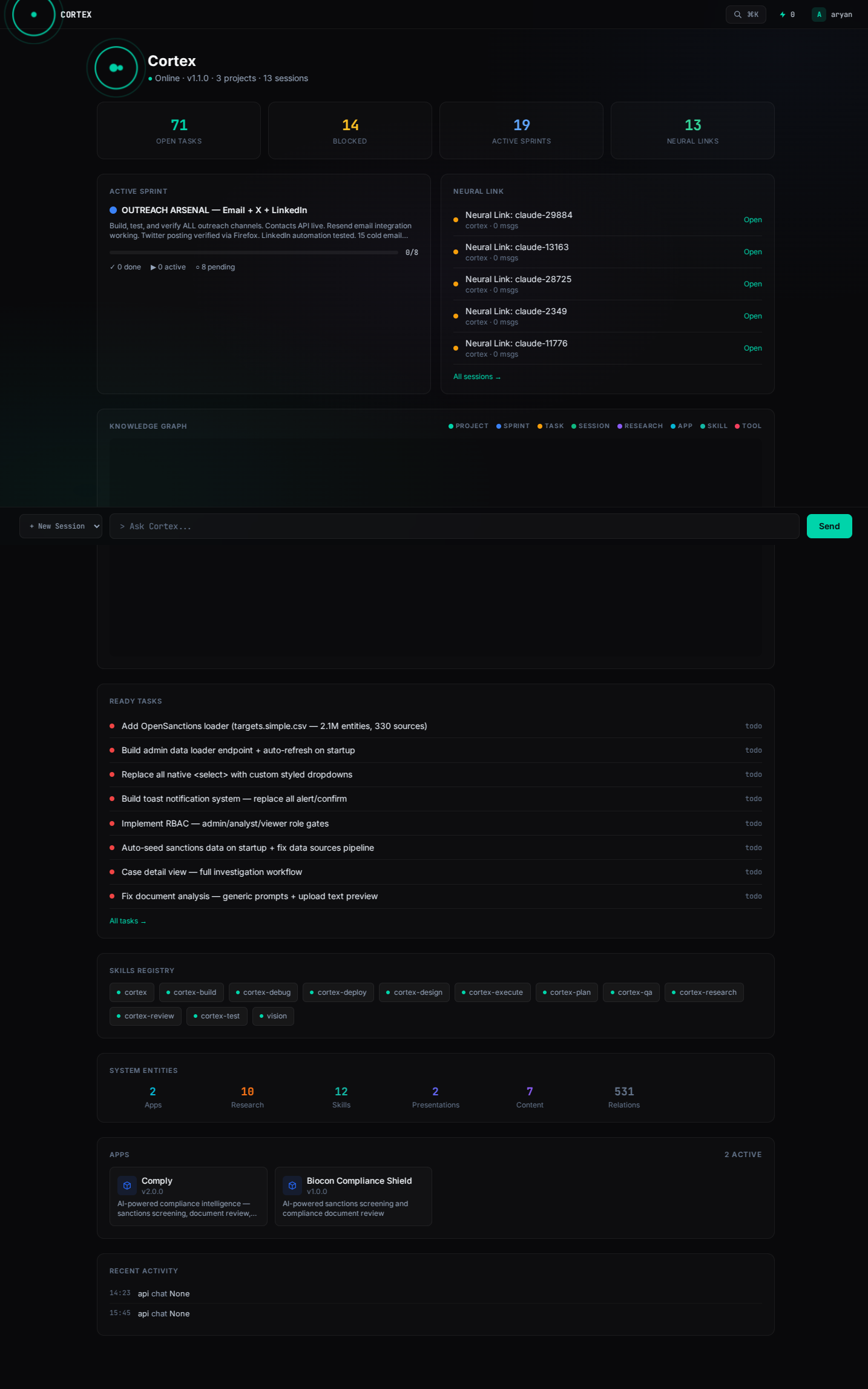
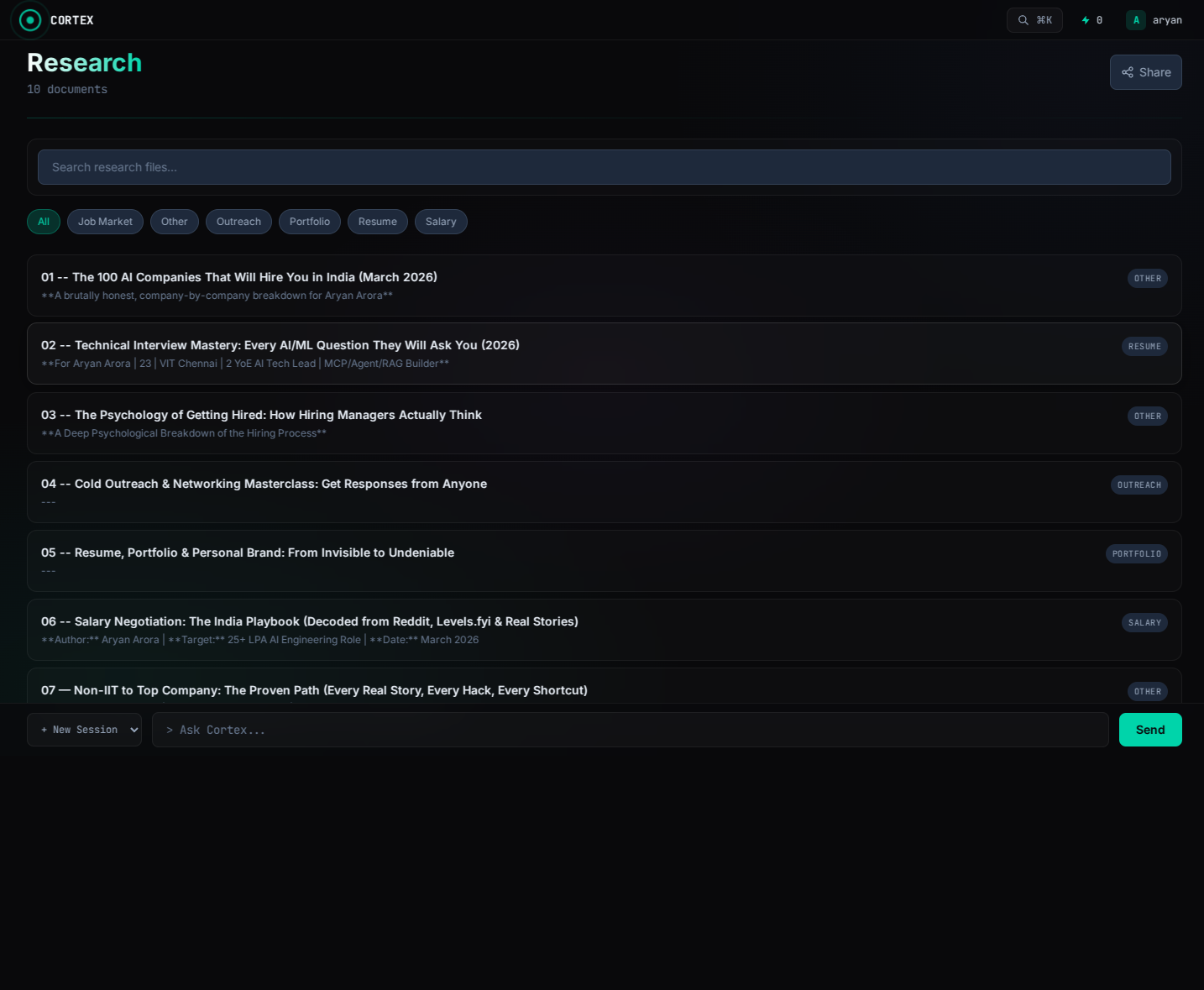
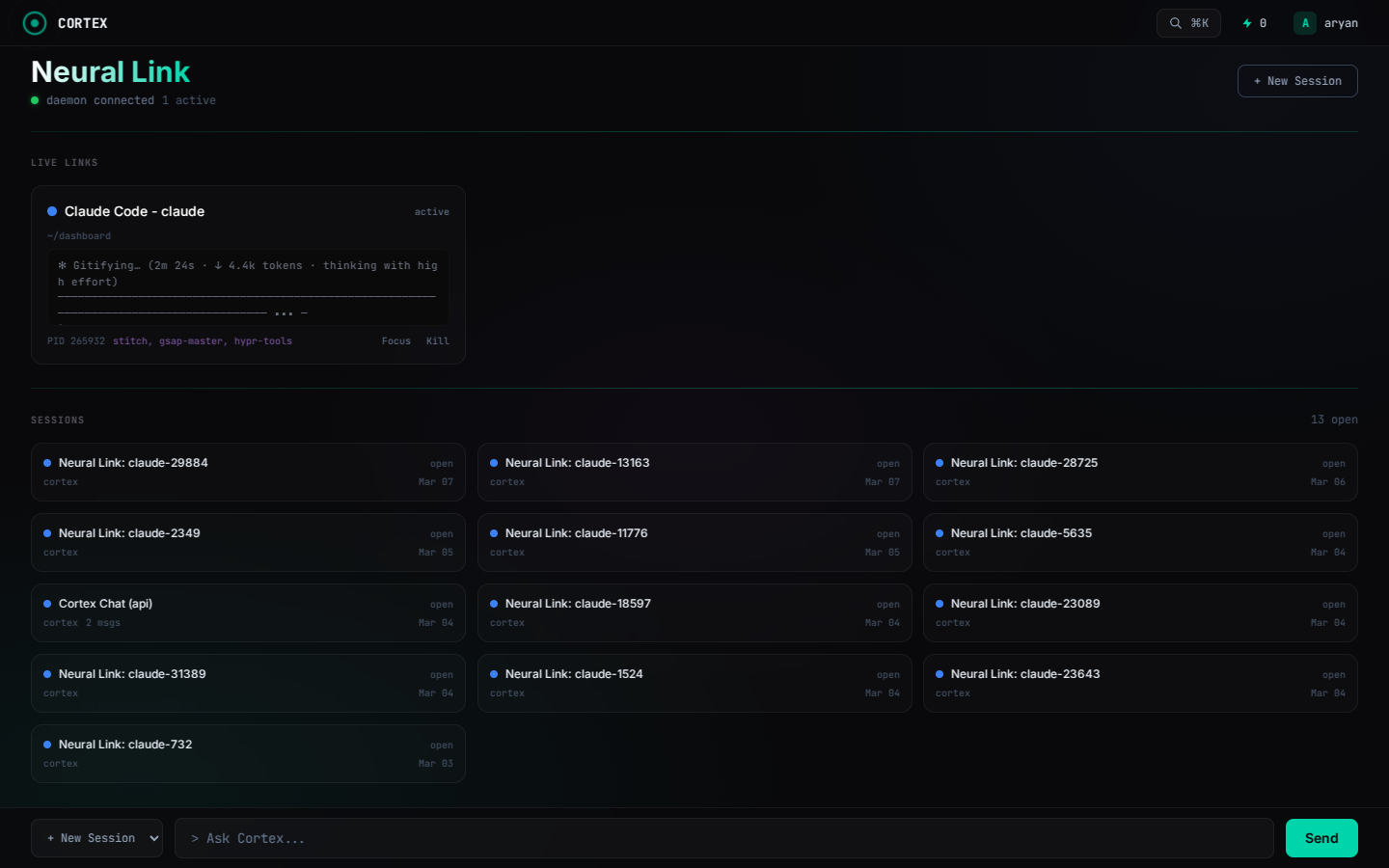
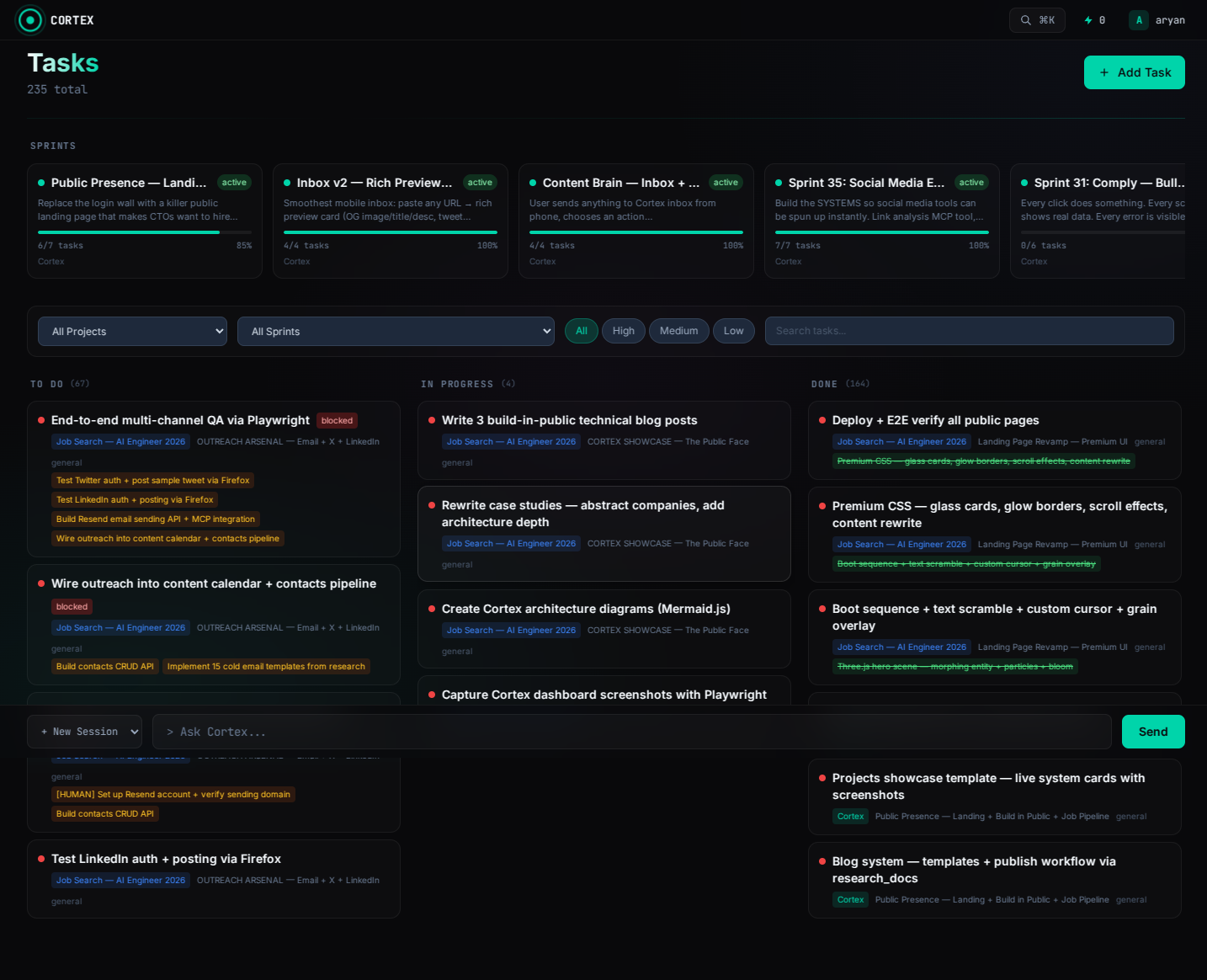
Screenshots